Title here
Summary here
An EHR Benchmark for Few-Shot Evaluation of Foundation Models
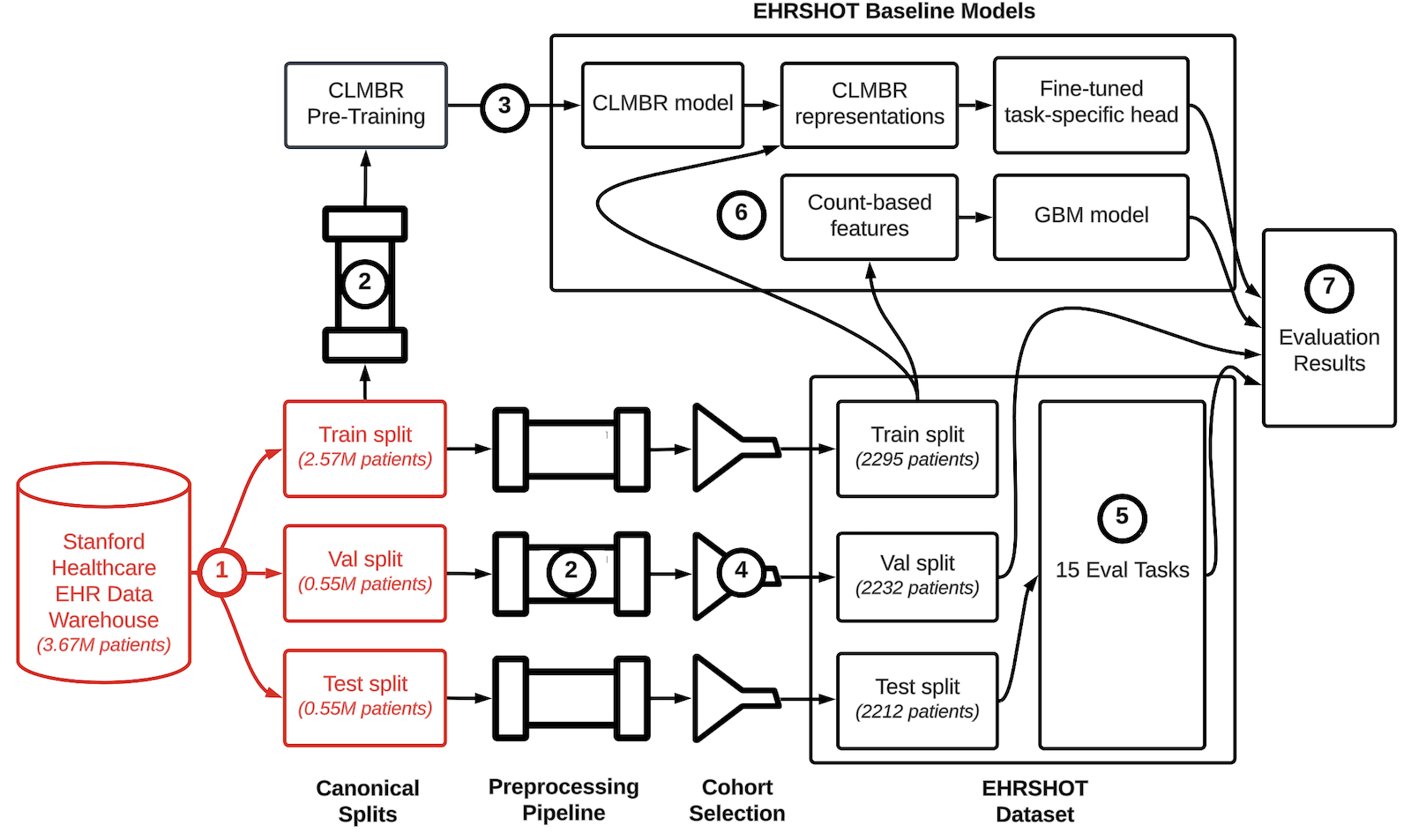
We collect the structured data within the deidentified longitudinal EHRs of patients from Stanford Hospital.
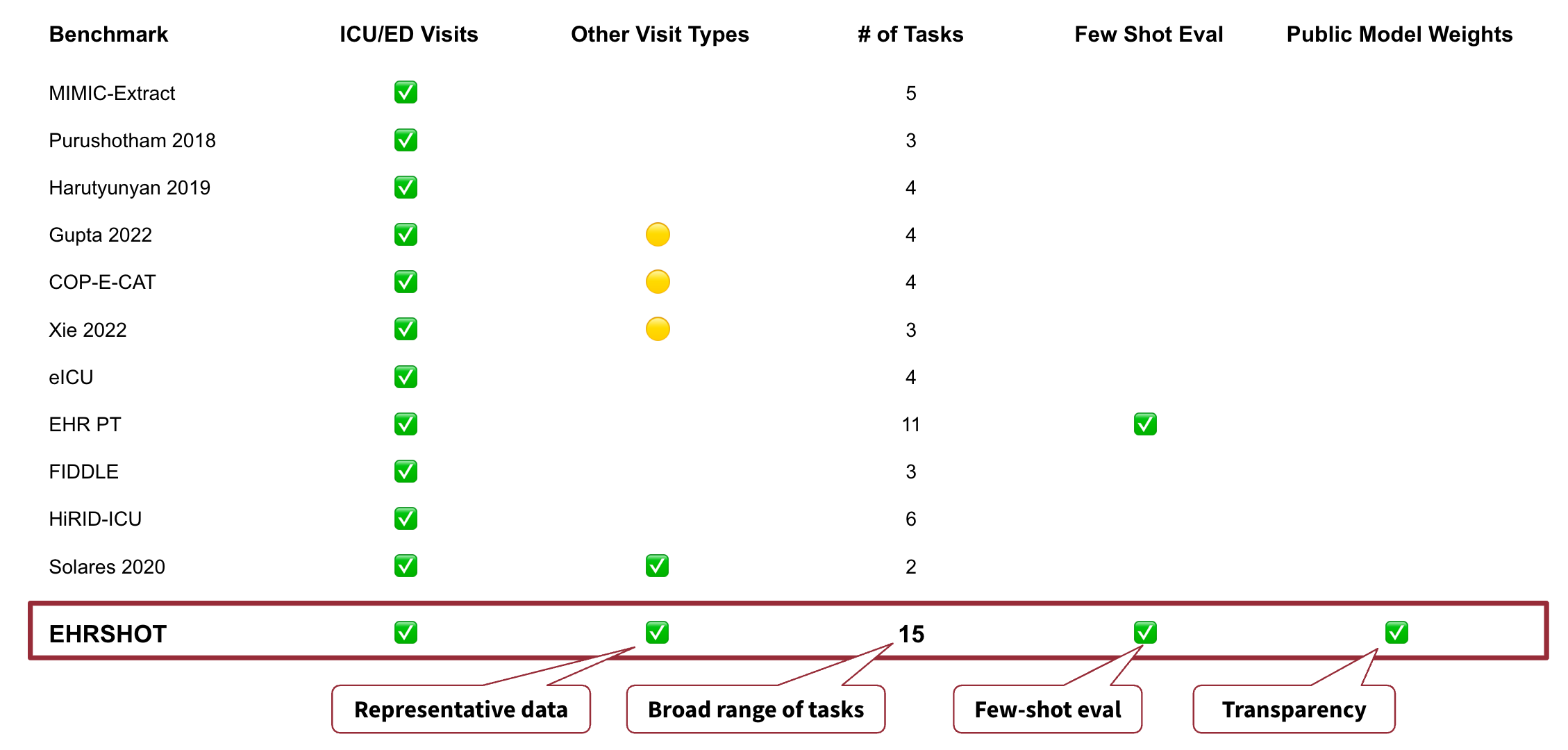
Most prior benchmarks are (1) limited to the ICU setting and (2) not tailored towards few-shot evaluation of pre-trained models. In contrast, EHRSHOT contains (1) the full breadth of longitudinal data that a health system would expect to have on the patients it treats and (2) a broad range of tasks designed to evaluate models' task adaptation and few-shot capabilities.
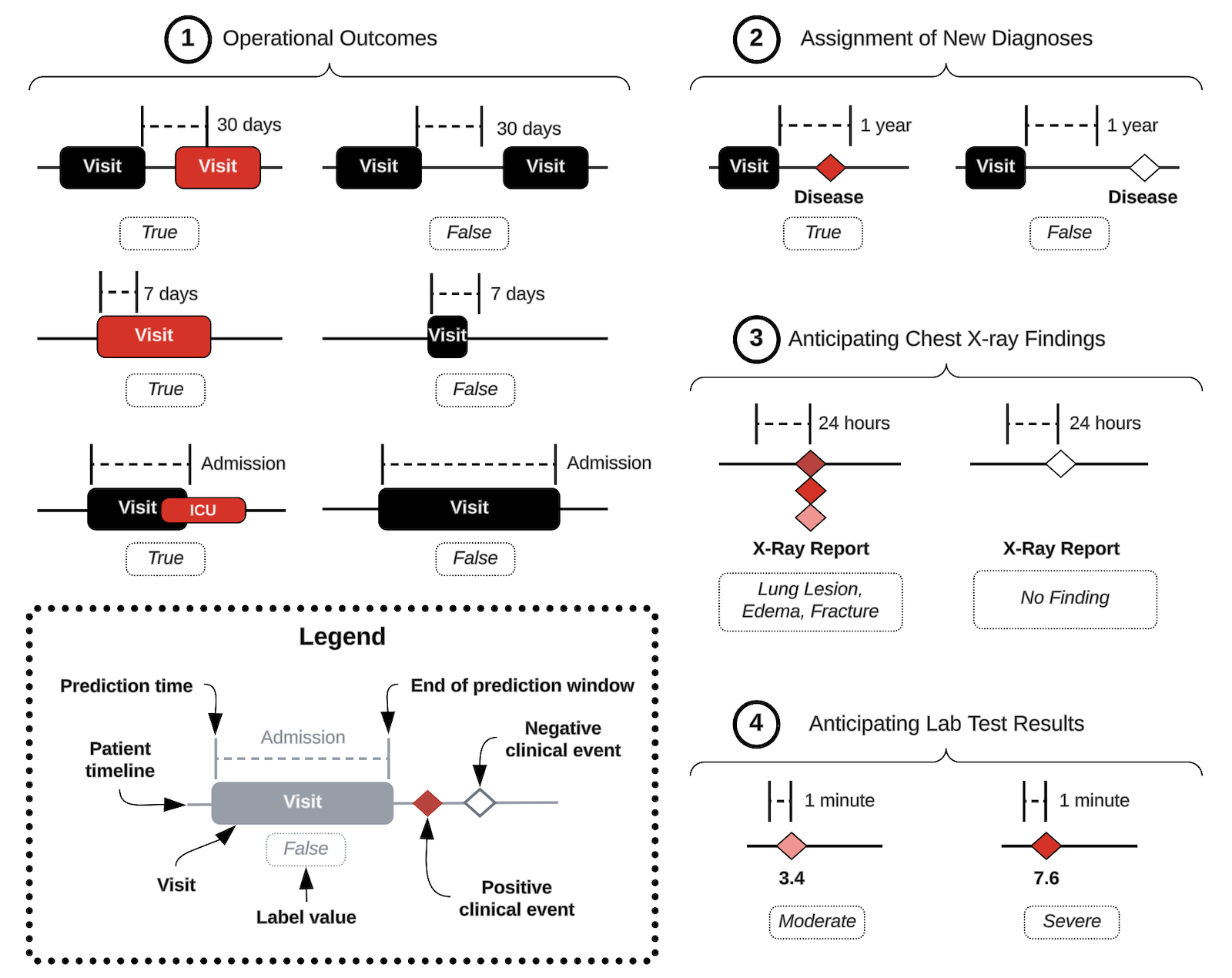
EHRSHOT includes 15 clinical classification tasks with canonical train/val/test splits, defined as follows.
| Task | Type | Prediction Time | Time Horizon |
|---|---|---|---|
| Long Length of Stay | Binary | 11:59pm on day of admission | Admission duration |
| 30-day Readmission | Binary | 11:59pm on day of discharge | 30-days post discharge |
| ICU Transfer | Binary | 11:59pm on day of admission | Admission duration |
| Thrombocytopenia | 4-way Multiclass | Immediately before result is recorded | Next result |
| Hyperkalemia | 4-way Multiclass | Immediately before result is recorded | Next result |
| Hypoglycemia | 4-way Multiclass | Immediately before result is recorded | Next result |
| Hyponatremia | 4-way Multiclass | Immediately before result is recorded | Next result |
| Anemia | 4-way Multiclass | Immediately before result is recorded | Next result |
| Hypertension | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Hyperlipidemia | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Pancreatic Cancer | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Celiac | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Lupus | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Acute MI | Binary | 11:59pm on day of discharge | 1 year post-discharge |
| Chest X-Ray Findings | 14-way Multilabel | 24hrs before report is recorded | Next report |
We include a graphical summary of the different task definitions below.
We evaluate each baseline model in a few-shot setting. For each of the 15 benchmark tasks, we
steadily increase the number of examples k that each model sees from k = 1 to the full training
dataset, and record the model’s AUROC and AUPRC at each k.
In the below figures, the bolded lines are the Macro-AUC for each model within
a task category, averaged across all subtasks at each k. The lighter lines are the AUC for
each model on each subtask.
We include the performance of each model trained on the entire EHRSHOT training split on the far right of every plot as "All".
Check out the Leaderboard for up-to-date results.


@article{wornow2023ehrshot,
title={EHRSHOT: An EHR Benchmark for Few-Shot Evaluation of Foundation Models},
author={Michael Wornow and Rahul Thapa and Ethan Steinberg and Jason Fries and Nigam Shah},
year={2023},
eprint={2307.02028},
archivePrefix={arXiv},
primaryClass={cs.LG}
}